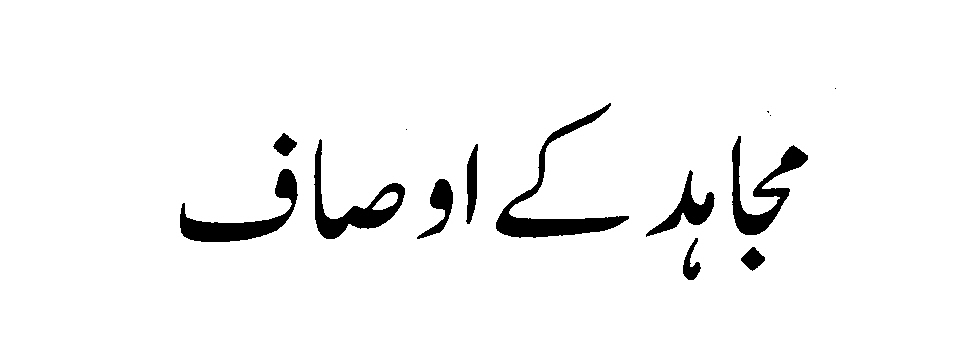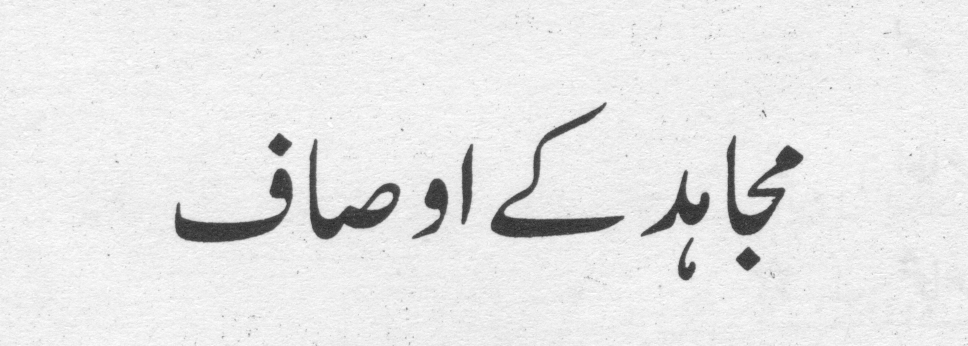| |
| |
[ Text Corpora ] [ Image Corpora ] [ Lexical Resources ] [ NLP Applications ] |
|
| |
[ How to Order ] |
|
| |
 |
|
| |
CLE is making these linguistic resources available without cost for supporting academic, non-commercial research. The processing fees being charged will be used to maintain these resources. You are requested to contact CLE directly for any discounts (applicable only for selective public organizations in Pakistan) or for commercial licensing options.
|
|
| |
|
|
| |
CLE Urdu Image Corpus 40 Point Size |
 |
[ Pakistan ] [ International ] |
| |
|
| |
| Source: |
|
| CLE Catalog #: |
CLE14I035 |
| Release Date: |
6 November 2014
|
| Data Type: |
Image |
| Language(s): |
Urdu |
| Distribution: |
1 DVD, Web Download |
| Processing Fee (Pakistan): |
30000 PKR |
| Processing Fee (International): |
250 USD |
| License: |
Yes |
| |
|
|
| |
Introduction |
| |
CLE Urdu Image Corpus for 40 Point Size is an image corpus collected from 23 Urdu books and three Urdu magazines written in Noori Nastalique writing style. The selected books have coverage of Urdu character set, Urdu digits, Latin digits, English characters, Urdu aerab and special symbols of Urdu. The variety of publisher, publication date, paper, printing and transparency qualities have also been ensured during the selection of books. These books have been selected from different domains (if available) such as literature, poetry, religion, biography, novel, interviews, culture/travel, history, autobiography, science, short stories and character representation. Heading images from each book are scanned at 300 DPI. Both gray scale and binary formats (if possible) of one hundred and ninety nine (199) images have been generated. The complete information (page number, domain, print quality, paper quality, transparency etc.) about each scanned page of the book is maintained in separate file. Typed corpus of images is also available at CLE Urdu Text Corpus 40 Point Size. |
| |
|
| |
Data Source |
| |
CLE Urdu Image Corpus for 40 Point Size is collected from 23 Urdu books and three Urdu magazines. The books information is maintained in a separate file which will also be distributed along with corpus.
|
| |
|
| |
Data |
| |
This corpus contains 26 folders, one folder for each book. Unique identifiers have been assigned to 26 folders representing the book IDs. There are two sub folders inside each folder. The details of each folder are as follows:
-
Headings_BW: This folder contains binary version of headings extracted from scanned images, in JPEG format. Each image name is labeled as follows:
BW(Black and White)_B<Book ID>_H(Heading)_P<page number>_H<heading number>_F<font size>
- Headings_GS: This folder contains grayscale version of headings extracted from scanned images, in JPEG format. Each image name is labeled as follows:
G(Grayscale)_B<Book ID>_H(Heading)_P<page number>_H<heading number>_F<font size>
|
| |
|
| |
Samples |
| |
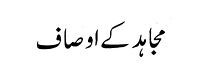 |
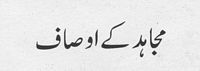 |
|
| Binary Heading Image |
Grayscale Heading Image |
|
|
| |
|
| |
|
| |
|
| |
|
| |
|
|
|
|